I Built a CRM Twice with AI
The autonomous version shipped code; the human-in-the-loop version gave me ownership.
I built a Customer Relationship Management (CRM) system for a successful small business - twice - to channel my unease about AI into a practical experiment.1
The first implementation was a fully hands-off, autonomous build, where I wrote the spec, then unleashed coding agents to implement and test. My involvement was approving and lightly critiquing the diffs, and the end result was the product shipped. It worked well enough to get users testing it. It also left me feeling like I was renting the code rather than owning it.
So I built it again, this time with a human-in-the-loop workflow (SolveIt) that forced me to stay close to the work. Not only did this V2 ship with the same effort, but more importantly it changed how I felt about the project.
Headline Observations
Here are my takeaways:
- Building this with autonomous agentic AI took as long as building it with AI-assisted development but came with significant downsides.
- The hands-off agentic build shipped fast initially, but long-tail issues resulting from poor oversight caught up to me.
- This autonomous approach stripped me of ownership and understanding; it became exhausting to even start working on it.
- The V2 build was done with SolveIt, which felt like a happy medium for AI-enhanced development - the resulting backend code was ~24% leaner, mostly due to smarter abstractions and cleaner boundaries
- A CRM system is so nuanced that anyone building it in house had better account for far more work than a few smart prompts.
- The system is now in alpha testing with one customer, but requires more work before it can be released publicly.
Why build a CRM?
I have a personal connection to a local small trades business that does millions in turnover each year, with a group of travelling sales folk. It is exactly the type of business that is highly resistant to change: their current approach is clearly working, and, as a trades business, they use as little software as possible. Buying and integrating new software is currently a non-starter.
I charmingly annoyingly told them I would build some software for free if it addressed one of the major pain points for the sales staff or management team. After a few discussions, a simple CRM came out top of their wishlist — something the team could use while constantly out on the road.
So while planning the system, I rode around with some of the sales team, documenting what mattered to them when dealing with clients. I also interviewed the sales manager and admin to get the lowdown on their biggest pain points.
Building a CRM also gave me a way to test the SaaSpocalypse claim in a real setting. CRMs are one of the obvious targets for AI disruption, but after doing this, the truth feels like most things: somewhere in the middle.
Version 1 — The Hands-Off Agentic Build
Once I had a rough idea of what I wanted to build, I spent the majority of my initial time developing the design spec. This felt very different to how I had approached things in the past, where there would be a high-level plan followed by a PoC build to get a true understanding of the project and its nuance.
In this first iteration of the CRM, all my brainpower was spent thinking it through in English. I found this exhausting — moreso than thinking while building, which had been my traditional approach. The benefit was that I had AI tools to bounce ideas off and help identify design or architecture gaps you would normally find during the PoC build. The key was having enough discipline to ask the right questions: poke and prod for feedback, missing architecture, and hidden assumptions.
The output — after two days of intense brainstorming — was an incredibly detailed spec doc, testing success criteria, and an implementation plan.
It Shipped
I created a repo with these docs and watched as sandboxed Codex GPT-5.4 and Claude Code Opus 4.6, both in YOLO-mode, started crushing the implementation. I watched in awe and horror as features contorted into existence. Initially it was thrilling — the app appeared to be built before my eyes.
And to give this approach its due: the first draft of the app was actually developed, users were testing it and providing feedback within a few weeks, and it did not cost more than my monthly Anthropic and OpenAI subscription costs. For many people and many use cases, that result is enough.
Boring Work Automated
What didn't change throughout V1 or V2 is that coding agents were genuinely useful at automating the things I didn't care to learn or work through: deployment, observability, TestFlight, App Store Connect, Firebase, widgets, notifications, and much of the Flutter app itself. These are real, annoying, project-killing details. I didn't care about loss of ownership here because I never intended to deeply own these bits; they were a means to an end.
Knowing where this boundary exists is key to using agents effectively: outsource the roadblocks that would have prevented you from completing the task even if AI coding didn't exist. I was always going to care about the backend because that is the crux of the business problem I am solving. The distribution channel, deployment, observability, widgets, notifications, and app-store nonsense were necessary but tedious details that pre-AI me may have given up on, rendering the project dead in the water.
The Bill Came Due
According to the default SV entrepreneur playbook, the above approach (quick to ship, outsourced tedious stuff) is the path to success. Based on that criteria alone, the first iteration was a success. However, the sneaky unexpected reality of this approach was that every follow-up change became exhausting.
Agents are tireless and relentless; with enough context and time, they can re-enter a codebase easily enough. I on the other hand have fixed resources, which meant I really struggled to re-enter the problem cleanly given I had such a flimsy grasp of the system's details. I had outsourced enough of the implementation that I often did not know what questions I should be asking anymore.
For a new feature request or a bug fix, I first had to understand whether I was dealing with a product roadmap decision, a schema issue, a missing integration, a prompt specificity problem, a bad abstraction, a deployment quirk, or just something the agent had confidently half-implemented that I missed. Every change was met with an increasing mental load. Before I could ask the agent to fix anything, I first had to reconstruct (and often rebuild) the mental model of the thing I supposedly owned. For all I had heard about AI lowering the inertia to start, this AI-developed CRM system introduced more inertia over time.
By the end of this version I wasn't really a developer anymore. I was a spectator hitting approve; an accept kiddie, a feature kiddie entirely dependent on the oracle interpreting my increasingly vague prompts.
The 97 Passing Tests Problem
One of the clearest failure modes atypical to traditional development (and there were several) came after the agent first declared the build complete. The 16-step plan was executed, all 97 tests passed, and all acceptance checks were green.
Something still felt wrong, though I can't recall exactly what (let's call it intuition from skimming the agent trace), so I asked a fresh agent to audit the acceptance criteria. It found that the core pipeline function was still a stub. Every layer below it had tests, but nothing actually plugged them together.
The failure was more sneaky than just “the agent forgot a feature” that clearly had been discussed and implied throughout - the system reported complete because every isolated component was green, while the product’s main path had never been wired up. I found that no matter how much effort I put in up front, either the spec or tests weren't detailed enough or the model just forgot to implement things, and there was no consistency for when each failure mode — lack of planning vs lack of execution — would appear.
I am fairly confident that if I had written the acceptance criteria myself, this type of oversight wouldn't have happened. Yes I would have missed other things, but I am finding humans make relatable and often understandable mistakes; the agents make bizarre mistakes confidently, as if it has no common sense. As it stands, my feeling is these coding agents are great coders but poor engineers.
Renting the Code
The 97 passing tests issue was the concrete failure, but realistically, it was findable and fixable: the first proper E2E test or agent testing loop would have caught it. The deeper problem was more personal and unexpected - the impact on my sense of ownership.
Simply put, at some point, I started to feel like I was renting the code rather than owning it. If I needed Anthropic or OpenAI to implement every change, explain every abstraction, and answer basic questions about the codebase, then in what meaningful sense was it mine? It really started to feel like a software version of the right-to-repair argument: if I cannot repair the thing without asking the manufacturer, do I own it or am I just licensed to use it?
One could argue this is just a moral stance, and I honestly would have said the same thing before starting this experiment. However it turns out for me, ownership matters. People take different care of something they own versus something they rent.
I can already hear the comments like "So what if you don't own it? Most businesses run on software they don’t understand. If the app works, who cares?" But this isn't just a vanity thing - ownership matters because when I own a system, I carry it around with me. I think about it in the shower, derive better abstractions while driving, wake up with a fix for the awkward edge case, and feel some pull to go the extra mile. With V1, that background process went quiet. The code did work, but it did not live in my head. Every change was a cold start, and cold starts are where care takes a backseat.
That matters for any software, but especially for a CRM handlinsg real business workflows and eventually sensitive customer data. The boring extra work - hardening, testing, privacy, edge cases, documentation - is exactly the work you lose sleep and obsess over only when you feel responsible for the thing.
I came up with my own litmus test for AI-built software: could I rebuild it again, or at least describe its core components with enough detail from my own recall and notes? If not, then I might have shipped something, but I did not really own it.
Other Costs of Distance
There were other failure modes I am keeping brief because each could become its own post.
First was drift. Scope creep became harder to resist because everything felt cheap. A bug would appear, I'd paste the error trace or more often just say 'fix it' without any thought of scope consequence. Despite every intention to stay fully engaged, I (and I would argue most devs) do not have the necessary discipline to watch and think of consequences when reviewing agent actions or generated code diffs. This is one of the more insidious behaviours of agentic coding: because the marginal cost of “just adding it” feels low, the discipline required to say no gets exponentially higher.
Second was skill atrophy, and I really felt this. Alberto Romero describes this well in How AI Is Taking Away Your Ability to Do Your Own Work: the more I only evaluated AI output, the worse I got at thinking. It wasn't even laziness (although that was a part), it really did feel like a blunting of my engineering skillset.
I fell into this trap hard in V1. The better the agent got at doing the work, the easier it became for me to stop doing the thinking. But using AI well is directly related to how well you understand the thing you are asking it to do. Once I stopped actively shaping the implementation, I also got worse at steering it.
Chicken Admin
One funny (yet scary) interaction from March 12th (whatever Claude Opus version was available then):
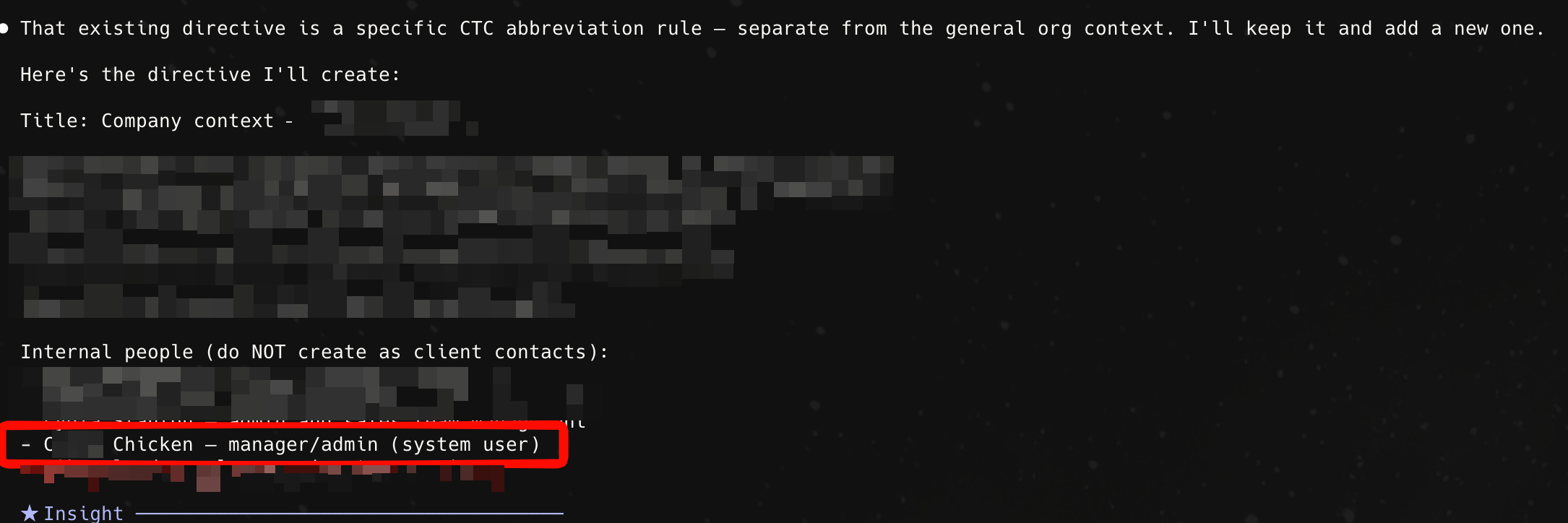
For the record my surname is not Chicken nor did I mention anything about chicken ever in the context. I honestly have no idea where this came from - it is so weird.
Version 2 — Human-in-the-Loop with SolveIt
What does a stubborn dev do after all that? Rewrite the whole thing — not necessarily with less AI, but with less distance from the work, and therefore much more ownership.
Below is my experience with SolveIt. I have no association with them. If nothing else, take away that IDEs with added friction, when done right, lead to fast implementation without compromises.
Just Enough Friction
You will find out as I write more that Jeremy Howard is a (parasocial) mentor of mine. Jeremy's latest project is SolveIt, which deserves its own post, but the briefest summary is this: SolveIt is the most effective human-AI coding collaborator I have experimented with so far.
SolveIt uses AI, just like everything else now - AI is a tool that becomes either good or bad depending on how it is used. In SolveIt's case, it uses AI effectively by changing where I sit in the development process. The notebook-style layout means any agent code updates appears in front of me in executable cells that I can run and test. The AI conversation, code, outputs, notes, decisions, and experiments all live together. Context is literally the cells above in the dialog, not some invisible blob.
This framing sounds small, but it does change my relationship to coding with agents. In V1, I was approving diffs generated elsewhere. In V2, I was building in a shared workspace where the AI could help aggressively, but I could still see, question, rerun, reshape, and understand the thing as it emerged.
SolveIt creates just enough resistance to stop me from becoming an approval machine. It nudges rather than replaces; it helps me get to the right answer without letting me disappear from the process entirely.
Context and Contract
I kept coming back to these two words during V2 build. None of this is revolutionary (everyone and their grandmother has heard of LLM context management), but it helps me explain why using something like SolveIt is so effective.
Context is the most obvious one. It almost goes without saying that agents are only as good as the context they can see. But in SolveIt, context felt less like an invisible prompt blob and function calls and more like a working surface. The notes, code, outputs, and decisions were all sitting there above the next prompt. I could see what the model could see, and I could add/hide/update the context at any point and re-run to get another response.
Contract is a concept that deserves its own post, because it is fundamental to embedding agents into software, when you design around understood structured responses (aka. contracts). However in SolveIt's case, the contract is the part of the context that constrains the work: tests, schemas, function signatures, examples, API boundaries, prior patterns, AI discussions, and explicit decisions about what the system is or is not allowed to do. In V1, I handed the agent a large spec and simply hoped it would preserve the shape of the system over time, often having to remind it when I spotted some drift. In V2, I talked through the design, wrote some code/pseudocode, and had the AI refine it until we had a pattern or design that was solid. This was active engagement, and all of this back and forth was contained in the dialog's context, creating an operating contract the system adhered to.
For example, instead of just saying “build the reminder flow,” I would define the shape of the reminder flow in the dialog first, often by discussing with the AI as a design partner: things like data structures, expected failure modes, workflow patterns, injecting user preferences, and sensible tests. The AI would still do a lot of the implementation and formatting, but it was operating inside a visible set of constraints that I developed and thus understood.
This is what I mean by contract - actual pressure from tests, schemas, examples, function signatures, and documented decisions that made bad output harder to accept accidentally.
Frictional Velocity
The rebuild did not feel magically faster (took roughly about the same time considering the boost of having done V1 beforehand), but it felt fundamentally different. I understood the backend again due to these thoughtful constraints. I could explain the abstractions, change the system without dread, and the code ended up ~24% leaner. In practice, that mostly meant fewer duplicated concepts, fewer one-off helpers, and tighter integration of code elements all while developing at pace (ie. frictional velocity).
Caveat
It is not lost on me that V2 benefitted massively from V1 having been written a month or two before. But this also confirms my feelings that in order for an autonomous system to build effectively while you manage, it really helps (and may be a requirement) for you to have worked on something similar in the past (ie. experience).
My Conclusion
I have tried the hands-off approach, and while it was fascinating and I did learn some things, it is too hard to invest fully in this spec-only technique for systems that touch real business workflows and customer data, especially as a solo developer. I need active engagement when coding, and tools like SolveIt and others that promote that bit of friction in exchange for engagement - and ultimately a sense of ownership - seems the likely path forward for me.
What This Did and Didn't Resolve
I gently alluded to this earlier in the post, that the pace of AI development gives me a queasy feeling. Doing an experiment like this doesn't give me any control over progress and didn't really settle my nerves as such - these tools are very capable and probably will continue to get more capable. What I did get a sense of is if I continue to work on solutions for small successful businesses in the messy real world, that this much more human-in-the-loop approach is the only way I can ethically operate.
More Agents Can Catch More Bugs, But They Don't Solve Ownership
I am sure there will be folks who read this and suggest all of the downsides mentioned in V1 could be addressed with a more robust (and costly) coding agent harness, which is probably true for any of the concrete failure modes discussed. From Simon Willison's code polish prompts, to swarms and workflows to now loop engineering, the field is in flux in terms of how to operate in this new world. These may all be effective in their own right, but it does not solve the problem of understanding, inertia, and ownership.
This post is a summary, a CV of my effort, and exists as a point in time snapshot of how I felt during this work. The reality is the AI disruption is happening at such pace my perspectives may change many times over the next short while.
What Happens Next
The CRM is still alpha. It is being tested with one business and a handful of trusted clients, but there is lots of hardening work to do before releasing it publicly. I think the plan is to open source it.
I also want to explore use cases that I think swarms and workflows and multi-agents provide real benefit without the downside. One such area is stress-testing the system we have agonized over - stay tuned for work on this.
For now, the thing exists, real people are trying it, and I understand it well enough to keep improving it.
Disclosure
I used SolveIt to brainstorm and collate all of my journal notes, but the words and content are mine. Some AI formatting and spell checking was also done.
Footnotes
-
By “unease” I mean the constant personal and professional worry I have about the impact and uncertainty of AI: fascination mixed with displacement dread, empowerment and disempowerment in the same breath. I can't control any of this disruption, and reading endless predictions about agents replacing developers was only making me feel more passive. But I can do something — channel the resolver mindset, make the best of what’s at hand, force myself into a real problem inside a real business, and see whether building with as much AI as possible left me feeling more capable or more dependent. ↩