UUIDs are not great for agent use
but not necessarily for the reasons I thought
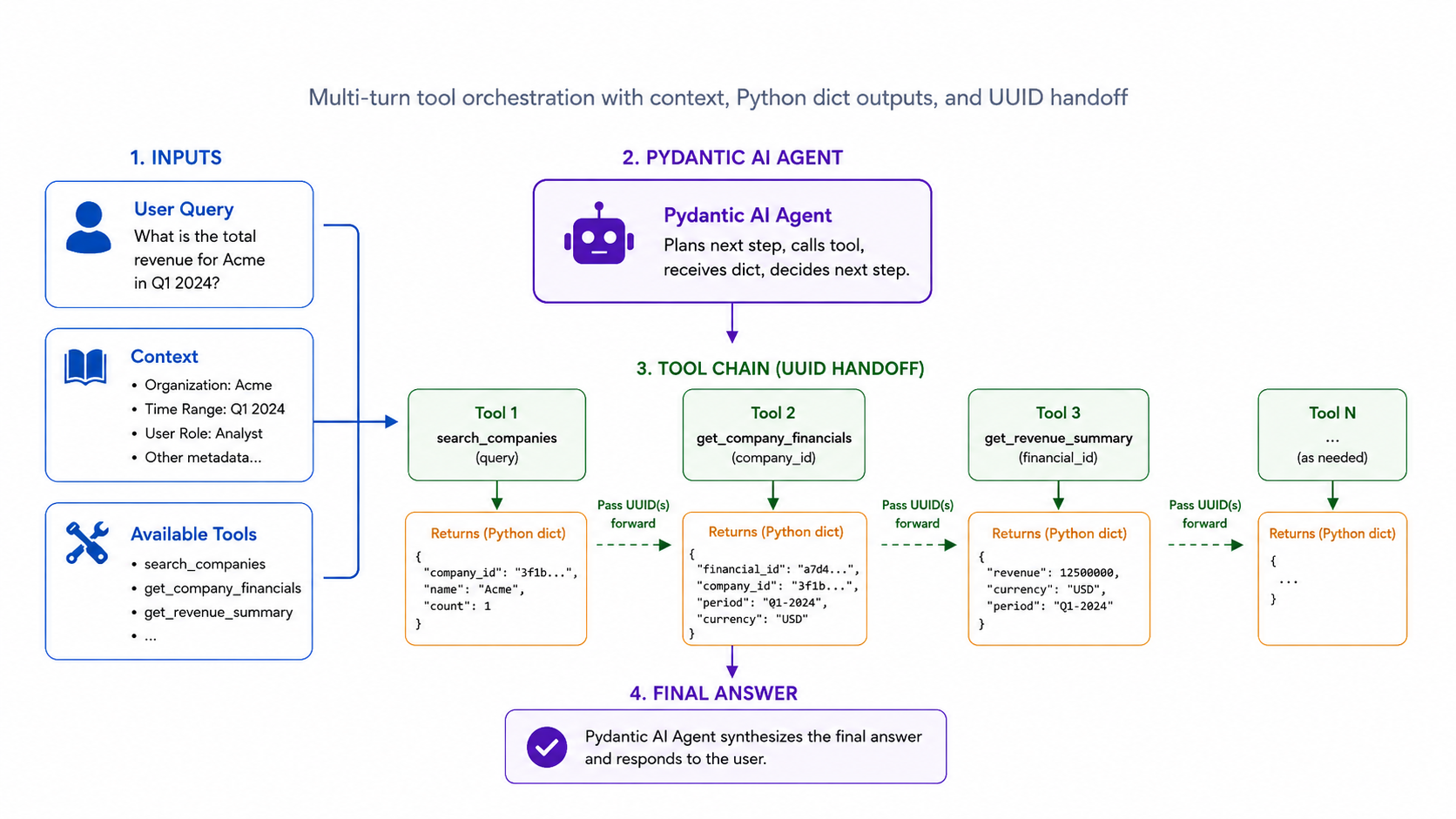
I set out to experiment whether using UUIDs in my agent's results would be affected by using these long IDs in the agent's workflow. I already had a suspicion these IDs would be problematic given how many tokens a UUID (~20 tokens, equivalent to a short-ish sentence) represents. I also saw this blog quantify just how much of an impact UUIDs had on agent performance, and I also was aware of this project that attempted to shrink the number of tokens of an ID. LLMs have also traditionally been bad at referencing things buried in the middle of their context window, which surely would be (unnecessarily) more complicated with complex IDs.
ChatGPT's interpretation of UUID tool calling
The problem was that up until now, the vibes of using UUIDs were fine. In using frontier models to prove a functional system, I never noticed an LLM mess up because of UUIDs being returned and passed around — no weird data or funky logs. Just like Simon Willison had indicated LLMs are getting better at following instructions, I've been having the same feeling about using UUIDs and how the frontier LLMs are getting quite good at using them in tools...I sure hope they are, as I am building a whole bunch of stuff on the assumption they can (eventually?) handle this effortlessly.
However, with Codex at my disposal I set it to try to build me some experimental conditions to test the hypothesis. We generated a deterministic employee directory with employee, manager, position, team, app, and role IDs. The agent had to call tools using exact IDs. We tested different ID types and measured how well the agent performed with each.
Results
Below is the results summary for gpt-5.4-nano:
| ID strategy | Correct | Accuracy | Invalid IDs | Wrong ID values | Cost |
|---|---|---|---|---|---|
| Raw UUID | 11/20 | 55% | 4 | 5 | $0.2052 |
| Integer remap | 19/20 | 95% | 0 | 1 | $0.0752 |
EMP-00001 typed sequence |
17/20 | 85% | 0 | 2 | $0.0886 |
| Readable hash | 12/20 | 60% | 0 | 9 | $0.1054 |
The more complex an ID, the worse the agent performed.
Why not compare gpt-5.5? It got everything right, regardless of the ID type (it also cost sooo much more to run). This was annoying, and I am sure this is too basic an experiment to test this frontier model thoroughly, but this was an interesting observation in its own right - not that it got it right, but weaker (and cheaper) models are impacted by the choice of ID, and these are the models we eventually want to use.
Bias Disclosure
While this was happening, I decided to implement the human-agent readable external identifier in my CRM app. I knew the result of the experiment (classic experimental bias) - it just made too much sense that an LLM will inevitably trip up on passing UUIDs to tools. So today was spent performing the public identifier boundary migration to expose public_ref on all agent-facing tables. I ran (and guided) the experiment towards demonstrating the poorer performance of UUIDs - a terrible scientific mindset. I also only took a cursory glance at the experimental code. However, I still learnt a bunch — see below. I just wouldn't quote this as any definitive evidence.
Public Refs are a good idea
Putting my poor experimental method aside, what I didn't appreciate was the cost impact, both directly (cost of UUID tokens) and indirectly (less confident using weaker models using UUIDs). Assuming even if the frontier models are superhuman at referencing the right UUID, using more readable and smaller IDs helps with 3 things:
- Easier for us (humans) to troubleshoot
- Token (and thus cost) effective
- More confident using weaker-but-cheaper models that do struggle using UUIDs, which is the ultimate goal - to use cheaper models within this CRM harness
If the public ref has a prefix like ACCT-, these typed prefixes also enable simple runtime validation to catch wrong-type tool arguments.
And depending on how you build the app, you don't even need to replace these UUIDs. If all of your database interactions and tool calls go through strictly defined functions, those functions become the boundary, meaning they expose the public ref to the agent while UUIDs stay internal as primary keys essential for preserving referential integrity.